Matplotlib气象色标模块的构造与使用
Table of Contents
1. 主要内容
- 制作
ColormapsPython 模块的目的 - 浏览已有色标
- 介绍、演示色标的使用方法
- 介绍
Colormaps模块的设计思路 - 探讨
Colormaps模块的改进 - (题外话)
git工具的日常使用 - (题外话)
conda-pack的使用
2. 制作 Colormaps Python 模块的目的
- 科研领域,色标使用往往较随意:
- 配色方案:“颜色感知平衡”即可(不推荐
jet,rainbow) - 色阶选择:便于说明问题即可
- 配色方案:“颜色感知平衡”即可(不推荐
- 产品领域:往往需要遵循固定色标:
- 国家气象局
- 北京气象局
- etc..
- 制作一个 Python 模块:
- 方便添加自定义色标
- 方便使用自定义色标绘图
- 快速完成产品开发
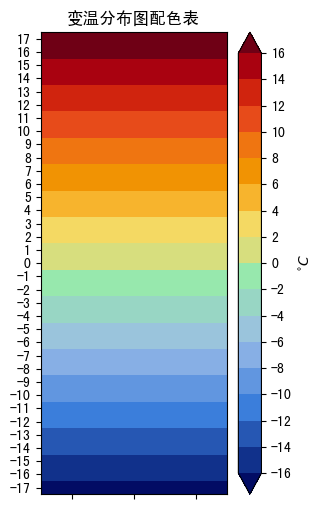
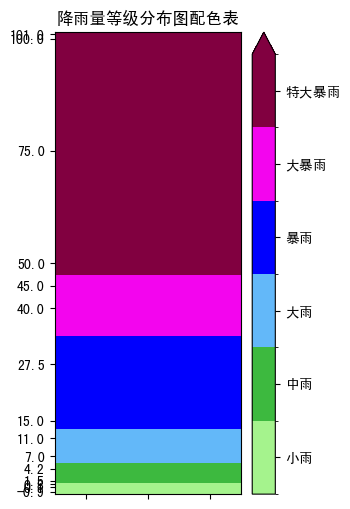
3. 已有色标举例
- 色阶是线性等间距的

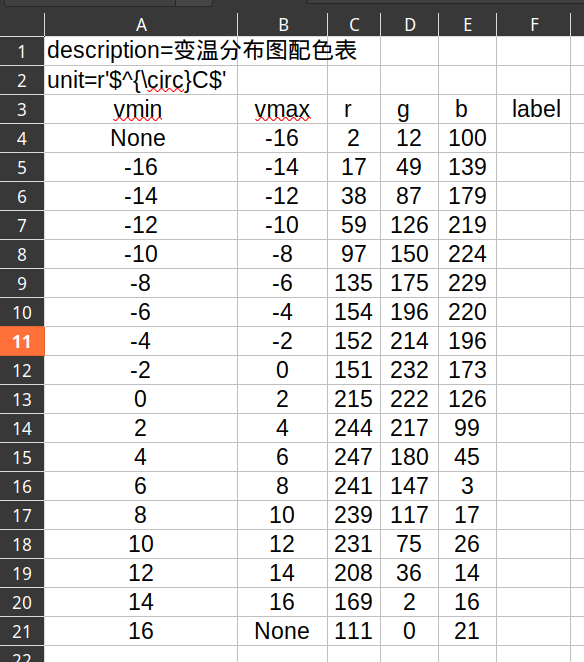
csv定义:
特点:
- 线性等间距色阶 (
levels):np.arange(-16, 16+2, 2) - colorbar
ticks与levels一样 - colorbar
ticklabels与levels一样
注意:
- 第一级的
None代表向下溢出,colorbar 下端是小三角 - 最后一级的
None代表向上溢出,colorbar 上端是小三角
- 线性等间距色阶 (
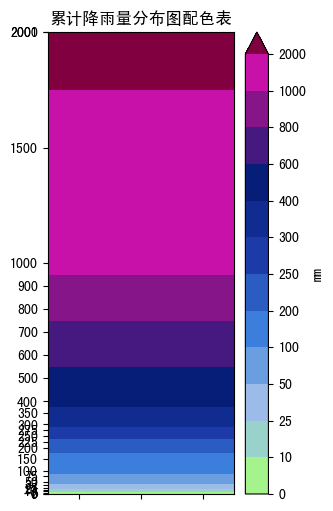
- 色阶是非等间距的
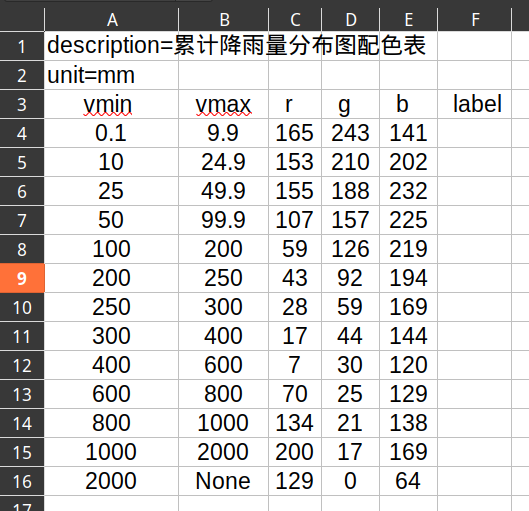
csv定义(与等间距的定义方法无差别):
特点:
levels非等间距- colorbar
ticks与levels一样 - colorbar
ticklabels与levels一样
注意: 对非等间距的
levels, 若想colorbar ticks仍以等间距画出,须 用spacing='uniform'. 否则默认spacing='porportion'将是类似左侧的 效果:cbar = fig.colorbar(cs ax=ax, spacing='uniform')
- 色阶是离散的、非数值的
csv定义:
特点:
- colorbar
ticks在色块中间,而不是两端(如下图) - colorbar
ticklabels是离散值,或是非数字的分类值(categorical)
注意:
label列定义了每个level使用的标签。- 当给出
label列的时候,colorbarticklabels将使用该标签,而不是levels的数值。ticks也将画在色块的中间,而不是两端
- colorbar
4. 介绍、演示色标的使用方法
- 把
Colormaps模块目录放到你能import到的地方 (后续实现了通过pip或conda安装后将没有这一问题)。 - 先执行一次
import Colormaps(原因之后细说) - 以 填色等高线 (
contourf) 为例:
import Colormaps from Colormaps import CMA_COLORMAPS # prepare your data ... XX, YY = ... data = ... # plot data fig, ax = plt.subplots() my_cmap = CMA_COLORMAPS.TEMP_CMAP ax.contourf(XX, YY, data, cmap=my_cmap.cmap, norm=my_cmap.norm, extend=my_cmap.extend) # plot colorbar cbar = my_cmap.plot_colorbar(ax, orientation='horizontal', spacing='uniform') fig.show()
其中:
cmap=my_cmap.cmap: 给出了配色方案norm=my_cmap.norm: 给出映射方法。在非等间距时非常关键extend=my_cmap.extend: 控制上、下溢出三角的绘制spacing='uniform': colorbar 色块为等间距
一个完整示例脚本见: Colormaps/examples/demo_sst_plot.py
结果图:
5. 介绍 Colormaps 模块的设计思路 (技术角度)
- 如何表征一个色标
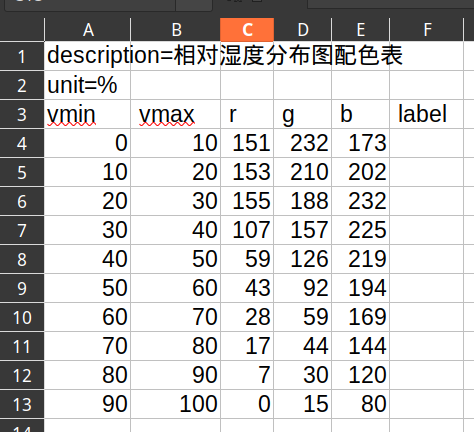
- csv表格:尽可能与标准参考资料中的呈现方式一致
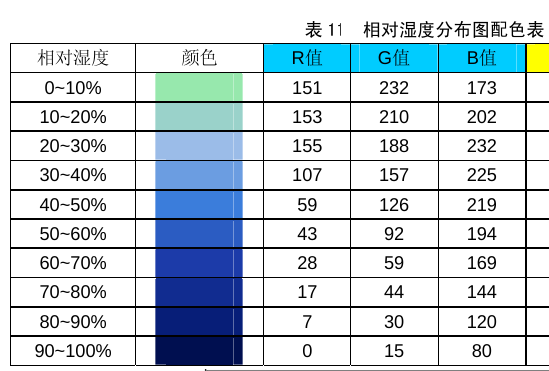
例如:《气象预报服务产品色标标准》中关于相对湿度分布的色标定义表格如下 (CMYK颜色部分截略):
与之对应的
csv定义表格:
使用这种设计的考量:
- 格式清楚易懂,能适应等间距、非等间距的色标
- 方便快速录入新色标
csv格式通用性好,不需要编程知识也能添加、维护色标
- 使用
namedtuple表征色标表格中的一行
将色标表格拆分成行,其中每一行使用一个
namedtuple表征:from collections import namedtuple Level = namedtuple('Level', ['vmin', 'vmax', 'rgb_tuple', 'label'], defaults=[''])
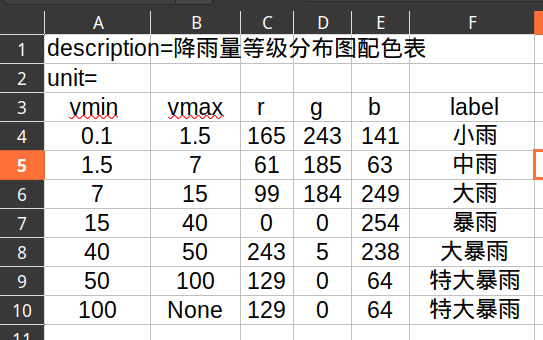
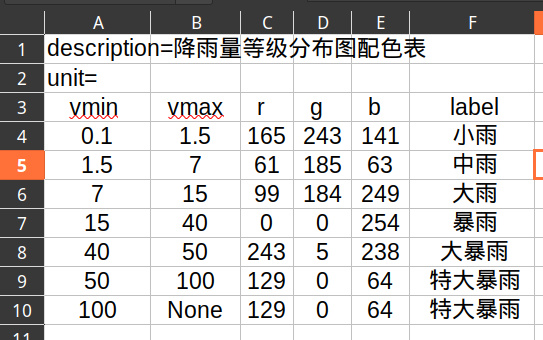
例如:
第一行的定义如下:
Level(0.1, 1.5, 165, 243, 141, '小雨')
使用
namedtuple基于的考量:- 与
csv表格的行可以一一对应,无附加格式上的转换 namedtuple相比class更小巧、轻量、简单namedtuple相比普通tuple描述性更好
- 与
- 使用
dataclass描述一个色标
一个完整的色标由多个
namedtuple组成,另外还需要“名称”、“单位”、“描 述”等数据。因此更适合使用dataclass来定义。from dataclasses import dataclass, field @dataclass class ColorMap: """Colormap class name (str): name of colormap, e.g. 'pre'. unit (str): unit of colormap bin edges/centers, e.g. 'mm'. level_colors (list): list of Level tuples, defining the levels and colors. description (str): text description of the colormap. """ name : str = '' unit : str = '' level_colors : list = field(default_factory=list, repr=False) description : str = '' ...
与
csv表格中内容的对应关系:name:csv文件名unit:csv文件的unit=行level_colors: 表格主体部分description:csv文件首行,为色标的描述文字
以上
dataclass类的定义基本上可以等同于以下普通class定义:class ColorMap: def __init__(self, name: str='', unit: str='',\ level_colors: Optional[list]=None,\ description: str=''): self.name = name self.unit = unit if level_colors is None: self.level_colors = [] else: self.level_colors = level_colors self.description = description
在
ColorMap中定义__post_init__()方法,用于将传入的level_colors数据做必要的处理,形成绘图需要的几个关键元素 (self.cmap,self.norm等):def __post_init__(self): if len(self.level_colors) == 0: res = self.init_default_levels() elif len(self.level_colors) == 1: res = self.init_single_level() else: res = self.init_from_levels() self.bin_edges, self.bin_centers, self.cmap, self.norm, self.extend,\ self.labels = res # colorbar ticks if all([x == '' for x in self.labels]): # if no labels, use boundary numbers as ticks self.ticks = self.bin_edges self.tick_labels = None self.spacing = 'proportional' else: # if labels provided, set ticks at level centers, and use uniform # spacing self.ticks = self.bin_centers self.tick_labels = self.labels self.spacing = 'uniform'
关于以下一行的写法:
self.bin_edges, self.bin_centers, self.cmap,\ self.norm, self.extend, self.labels = self.init_from_levels()
self.bin_edges等的属性赋值也可以在self.init_from_levels()内部 完成,此时该行就可以简单地变成
self.init_from_levels()
- 可讨论的地方:类的方法应该有多少个“出口”?方法返回值,类属性,二者同 时?方法、函数的“副作用”会影响代码可读性、可理解性,尤其在代码量大、 逻辑复杂的时候。
使用
dataclass的考量:dataclass是标准class的变体,相比普通class更适合包装 数据 为主 的类。使用dataclasses可以“免费”获得定义好的__init__(),__repr__(),__eq__(),__hash__()等特殊方法。- 作为学习的练手
- csv表格:尽可能与标准参考资料中的呈现方式一致
- 新色标的添加方法,第一版: csv 定义文件 + python 代码
要添加一个新色标需要做的:
- 在一个色标文件目录内,如
Colormaps/cma_colormaps/内新建一个csv文件,按如上举例的格式写入一个色标定义。例如snow_depth.csv - 打开
Colormaps/cma_colormaps/__init__.py代码文件 在代码文件中加入
csv读取命令:SNOW_DEPTH_CMAP = create_cmap_from_csv(os.path.join(SUB_DIR, 'snow_depth.csv'), CMA_COLORMAPS)
- 在代码文件中,修改名为
__all__的全局变量,将'SNOW_DEPTH'字段 加入到__all__列表中 - 如果要新增 一整个色标系列, 例如
Colormaps/wmo_colormaps/, 则除 了要添加csv文件外,还需要以固定格式要求新建一个__init__.pyPython 代码文件,其中有若干变量都需要设置正确的值(以避免与已有色 标系列冲突等问题)。
问题:
- 修改 Python 代码的步骤对非 Python 程序员很不友好
- 即便对 Python 程序员而言,由于需要多处代码修改,容易出错
- 不够“傻瓜式”
- 在一个色标文件目录内,如
- 新色标的添加方法,第二版: csv 定义文件 + 动态加载
新设计希望达到的效果:
- 增、删、改动色标完全通过
csv文件实现 - 无需修改一行 Python 代码
- 色标数据与代码分离,实现类似“插件”、“扩展包”的效果
- 在 Python 代码中,通过属性访问语法获取色标系列,和色标系列中的具体色
标。例如
Colormaps.RADAR_COLORMAPS是雷达相关的“色标系列”,或“色标 分组”。而Colormaps.RADAR_COLORMAPS.CR_CMAP是雷达相关“色标系列”中 的组合反射率色标。
新色标定义存放方式:
Colormaps/ # 项目根目录 colormap_defs/ # 存放色标定义的子目录 cma_colormaps/ # 中国气象局色标子目录 fog.csv # 雾区分布色标 rh.csv # 相对湿度色标 ... radar_colormaps/ # 雷达相关色标 cr.csv # 组合反射率色标 ... other_colormaps/ # 其他色标 ...在
Colormaps/__init__.py文件中加入以下代码:from .colormap import load_colormaps,\ DEF_FOLDER, ColorMap, ColorMapGroup,\ create_cmap_from_csv # load colormaps into this module's namespace names = load_colormaps(DEF_FOLDER) for name, obj in names: try: exec(f'{name} = obj') except: print(f'Failed to add name {name} to module namespace.') # remove these from namespace del names del name del obj del DEF_FOLDER
其中:
from .colormap import load_colormaps, DEF_FOLDER, ...: 主要函数、 类写在了Colormaps/colormap.py文件里,在此引入names = load_colormaps(DEF_FOLDER): 读取色标定义的目录,读取色标分 组信息和色标信息。返回的names是一个包含(ColorMapGroup_name, ColorMapGroup_obj)元组的列表exec(f'{name} = obj'): 执行形如CMA_COLORMAPS = cma_colormapgroup的赋值操作。之所以在__init__.py内把这些赋值成 全局变量,是为了方便用户可以执行Colormaps.CMA_COLORMAPS
的 module 内成员访问。
最后的几行
del命令,是清除不需要的全局变量,防止污染Colormapsmodule 的命名空间。这样的设计可以实现色标动态加载的效果。 但是一个副作用是:用户需要显式地
import Colormaps, 才能触发加载动 作(即load_colormaps()的函数调用)。
在用户执行
import Colormaps命令后,程序将自动读取
colormap_defs目录内的目录结构和csv文件,形 成如下层级关系:Colormaps # Colormaps 的模块命名空间 Colormaps.CMA_COLORMAPS # 中国气象局色标系列 Colormaps.CMA_COLORMAPS.FOG_CMAP # 雾区分布色标 Colormaps.CMA_COLORMAPS.RH_CMAP # 相对湿度分布色标 ... Colormaps.RADAR_COLORMAPS # 雷达相关色标系列 Colormaps.RADAR_COLORMAPS.CR_CMAP # 组合反射率色标 ... Colormaps.OTHER_COLORMAPS # 其他色标系列 ...Python 交互环境演示
cd ~/scripts/hxkj/weather_plot/import Colormaps Colormaps.<TAB> mycmap = Colormaps.CMA_COLORMAPS.RH_CMAP ...
成功获取了
mycmap色标实例之后,即可参考以上介绍、演示色标的使用方法 使用。 - 增、删、改动色标完全通过
6. 探讨 Colormaps 模块的改进
- 加入一些单元测试
已有单元测试:
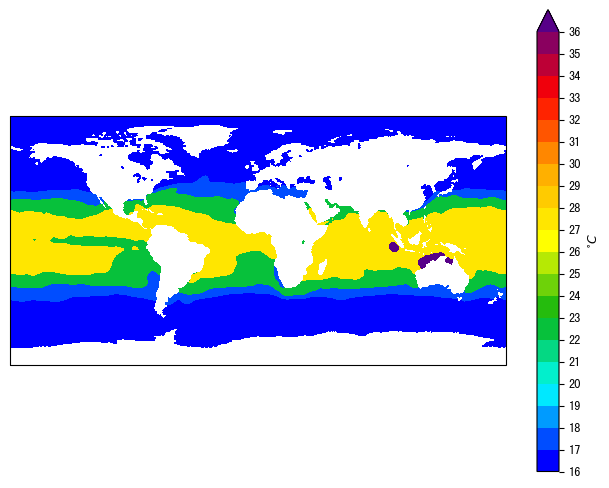
test_install.py: 测试依赖包是否已安装test_colormaps.py: 读取样例ERA5的海表面温度数据, 并 使用CMA_COLORMAPS.SST_CMAP绘制全球分布图(见图 1)
- 封装,上传 pypi and/or conda
使得
import Colormaps可以在任何位置执行。UPDATE: 已上传 Pypi:
https://pypi.org/project/geo-colormaps/pip install geo_colormaps - 用户自定义色标存放位置:在 pip, conda 安装时尤其重要
例如
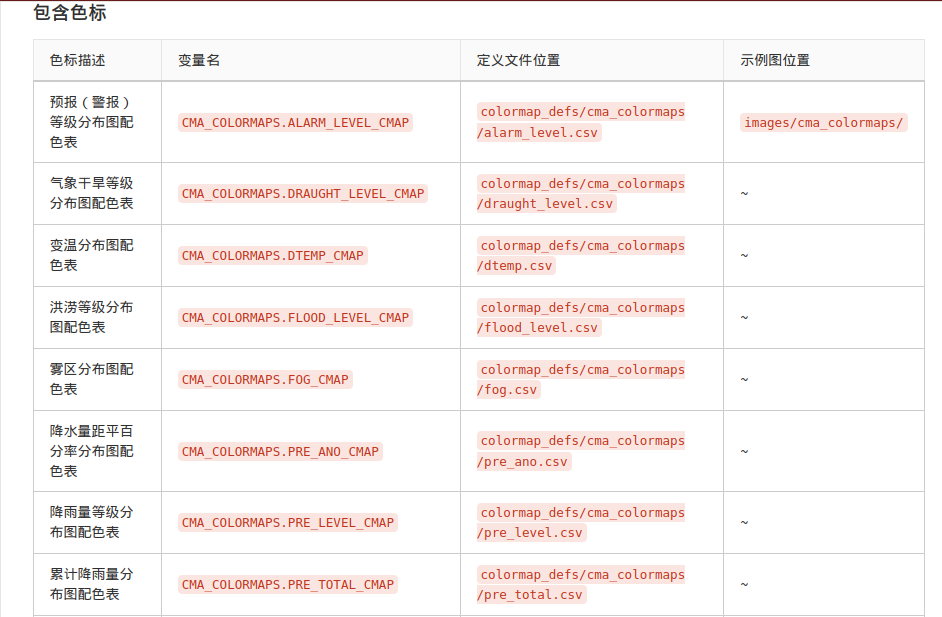
$HOME/.config/geo_colormaps/ - 自动生成 README.md 色标表格
现有表格截图(部分)
pypi的geo_colormaps包已实现。 - 已有色标均为离散类型色标,加入连续变化色标
7. (题外话) git 工具的日常使用
- 非日常流程
- 日常流程
- 1. 进入本地 repo 目录
- 2. 执行
git fetch获取远程 Gitlab/Github 上的更新
注意:
git fetch只会“瞅一眼”远程端 remote 上是否有新更新,并不会真 的拉取代码并覆盖本地的内容,因此是“安全”的,可以放心大胆地运行。 - 3. 若
git fetch命令有返回内容,则表明远端有新更新,此时先运行git pull拉取更新
此时推荐先运行
git pull拉取远端的更新,这样可以在最新的代码基础上进 行你的改动。当然如果你能确信你将要做的改动不会和远端的更新形成冲突,也可以先不拉取。 但这样很容易出问题,因为真的改动起来的时候可能会收不住
- 4. 进行本地功能开发
做代码的增、删、改。并进行本地测试。
- 5. 为自己的修改写
commit message
这一步骤中,我通常会开3个窗口,分别展示以下内容:
- 窗口1: 用 vim 显示代码
- 窗口2: 执行
git diff查看自己做了哪些修改。 - 窗口3: 执行
git status, 查看哪些文件待添加。然后执行git add, 选择性地添加修改的内容,或git add -A, 添加所有待添加的文件。 之后执行git commit, 并不断参考窗口1、窗口2内容,写commit message, 最后保存,完成 commit 操作。
- 6. [可选]继续进行若干个步骤5
git commit之后,改动仍然只发生在你的本地 repo, 只要不做git push操作,就不会影响到远端。因此,可以在本地继续进行代码开发。
推荐的做法:
- 组织自己的开发活动,使得每一个 commit 内发生的改动都关于一个明确的主 题。例如:一个 commit 内只做添加一个插值功能的改动,一个 commit 内只 做修改一个拼写错误的改动,另一个 commit 内只做某个绘图功能微调的改动。
- 宗旨是:使 commit 之间相对独立,每个 commit 有相对清晰的内容。不要在 一次 commit 做各种混杂的操作。
- 方便一旦出现问题的时候回溯引入问题的 commit,并进行回滚。
- 7.
git push上传代码
本地操作完后,可以执行
git push将本地代码上传。之后,另一位开发者(包括明天的自己),再次进行开发时,应该重新进入步骤 1:先检查远端是否有更新
git fetch, 如果有,拉取之git pull, 再进行 新一轮的开发。
- 1. 进入本地 repo 目录
- git commit 的时机
- 不一定要一项功能完整开发完之后才做
- 更推荐每天工作结束之前来做
- 一方面避免工作意外丢失
- 一方面缓解某种“强迫症”压力
- 经验:真正需要回滚错误的时候其实极少。更多的可能是心理上的调节作用, 此外帮助自己养成好的习惯。
git log:commit message的历史记录,便于追溯问题
- 其他非日常流程
git checkout -b new_branch: 新建分支
当代码将在重要的方向上发生改变、且完成后可能不会合并会
master时,例如:
或者将要开发的功能、修复不是三、两行就能完成时,例如
dev分支。完成 之后会合并会master.- git stash
例如: 我在
028分支上正在进行开发,未进行commit. 此时我需要临时切换回048分支上去(查看代码文件、或对048进行一个紧急修复)。此时,可执行
git stash
将
028分支上未经commit的修改临时存放到stash列表中,并将028分支内本地改动还原。再执行
git checkout 048切换到048分支进新紧急修复工作。之后,再
git checkout 028切换回028分支。此时,执行git stash list
可以看到之前隐藏的修改条目。条目最左端有条目的编号。此时执行
git stash pop
将之前临时收起来的改动重新拿回来,可以继续未完成的开发工作。
- 其它非日常流程
git merge: 合并分支。合并冲突的解决。- pull request: 提出合并请求。
8. (题外话) conda-pack 的使用
- 主要用途
迁移、部署一个
conda环境 - 基本流程 (Linux系统)
- 在开发机器上安装 conda,和一个 conda 环境(例如
my_env),并安装好所需 Python 包/库 - 在开发机器上安装 conda-pack: 推荐在
base环境下安装:(base) $conda install conda-pack - 在开发机器上打包环境:
conda pack -n my_env -o out_name.tar.gz - 将压缩包拷贝到部署机器上
在部署机器上,解包:
mkdir -p my_env tar -xzf my_env.tar.gz -C my_env
在部署机器上激活环境:
source my_env/bin/activate conda-unpack- 在部署机器上,运行python代码
- (optional) 在部署机器上,退出环境
source my_env/bin/deactivate
- 在开发机器上安装 conda,和一个 conda 环境(例如
- 基本流程 (Windows系统)
与 Linux 系统不同的是:
激活命令:
cd my_env .\Scripts\activate.bat .\Scripts\conda-unpack.exe
注意: 一定要使用 Windows 自带的命令行程序
cmd.exe, 不能使用Anaconda的命令行!!!PowerShell貌似也不行。 - 注意事项
- 1. 目标部署机器上需要安装有 conda
- 2. 开发机器的操作系统需要与目标部署机器相同
Linux 配 Linux, Windows 配 Windows. 不能交叉部署。
- 3. 尽可能不要混用
pip和conda安装
一旦环境中同一个包,如
numpy, 被pip和conda同时安装,conda-pack命令会报错。尽可能只用一种安装。
如果必须同时用
pip和conda, 推荐先把conda能安装的都装完。然后先用
--dry-runflag 运行一下需要用pip安装的包:例如:
pip install --dry-run fastapi, uvicorn, sqlalchemy
然后注意查看
pip会需要拉取哪些依赖,例如numpy,scipy之类。注意这些依赖的版本是不是与通过conda安装的同名依赖版本相 同。 如果版本不同的话,pip和conda将会安装两个不同版本的numpy, 最终导致conda-pack命令出错。如有版本冲突,可尝试在
pip安装命令中指定依赖版本。例如,conda已经安装了numpy 1.21, 在pip命令中指定之:pip install --dry-run numpy==1.21 fastapi uvicorn sqlalchemy确保
pip不会引入依赖包冲突之后,再去掉--dry-run运行一遍。 - 4. 删除一些可疑的
exe文件(如过甲方需要杀毒时需注意)
在解压后的目录,如
my_env下,运行find . -type f -path "*/distlib/*" -name "*.exe"
可能会发现如下搜索结果:
./lib/python3.9/site-package/pip/_vendor/distlib/w32.exe ./lib/python3.9/site-package/pip/_vendor/distlib/t64-arm.exe ./lib/python3.9/site-package/pip/_vendor/distlib/w64-arm.exe ./lib/python3.9/site-package/pip/_vendor/distlib/t64.exe ./lib/python3.9/site-package/pip/_vendor/distlib/t32.exe ./lib/python3.9/site-package/pip/_vendor/distlib/w64.exe
可运行以下命令将之删除:
find . -type f -path "*/distlib/*" -name "*.exe" -exec rm {} +
- 5.
cartopy地图文件
如果目标部署机器无法联网,则在开发打包阶段需要迫使
cartopy下载必要 的地图文件。在安装完
cartopy之后,在命令行里 可能 会有cartopy_feature_download.py命令。运行:cartopy_feature_download.py physical cultural
可下载地图数据。之后再使用
conda-pack打包,就可以将地图数据一起打包。*注意*: 高版本的
cartopy貌似不再附带cartopy_feature_download.py可执行程序。不十分肯定。 - 6.
matplotlib中文字体
仍然比较迷糊。
- 1. 目标部署机器上需要安装有 conda
Created: 2023-12-25 Mon 23:07

