Table of Contents
- 1. Overview
- 2. Parse the config file
- 3. Create the Darknet-53 model
- 4. Test drive
- 5. Summary
1. Overview
This is Part-2 of the series on building a YOLOv3 model from scratch.
Here is an overview of the series:
- Understand the YOLO model.
- Build the model backbone: This post. The backbone of YOLOV3 is a fully convolutional network called Darknet-53, which, as its name implies, has a total of 53 convolution layers. We will load the config file of the original YOLOv3 and implement it using PyTorch.
- Load pre-trained weights.
- Get the tools ready.
- Training data preparation.
- Train the model.
Also note that it is assumed that you have some experiences with building networks using PyTorch.
2. Parse the config file
YOLOv3 is a fully convolutional model. To implement it using PyTorch, we can use the paper and the config file as a reference and just write up our network module ourselves. Or, we can write some code to parse the config file, and assemble a model from the parsed model structure. This post will take the later approach.
The config file for YOLOv3 can be found in
the darknet repository, in the cfg/ folder, with name yolov3.cfg.
2.1. Understand the config file format
The config is a plain text file, with sections denoted by square brackets. Here is the first few lines of the file:
[net] # Testing # batch=1 # subdivisions=1 # Training batch=64 subdivisions=16 width=608 height=608 channels=3 momentum=0.9 decay=0.0005 angle=0 saturation = 1.5 exposure = 1.5 hue=.1 learning_rate=0.001 burn_in=1000 max_batches = 500200 policy=steps steps=400000,450000 scales=.1,.1 [convolutional] batch_normalize=1 filters=32 size=3 stride=1 pad=1 activation=leaky # Downsample [convolutional] batch_normalize=1 filters=64 size=3 stride=2 pad=1 activation=leaky
Some format explanations:
[ ]: beginning of a section/block. E.g.[net],[convolutional].#: comment line.key=value: key-value pairs.
2.2. Building blocks of the config file
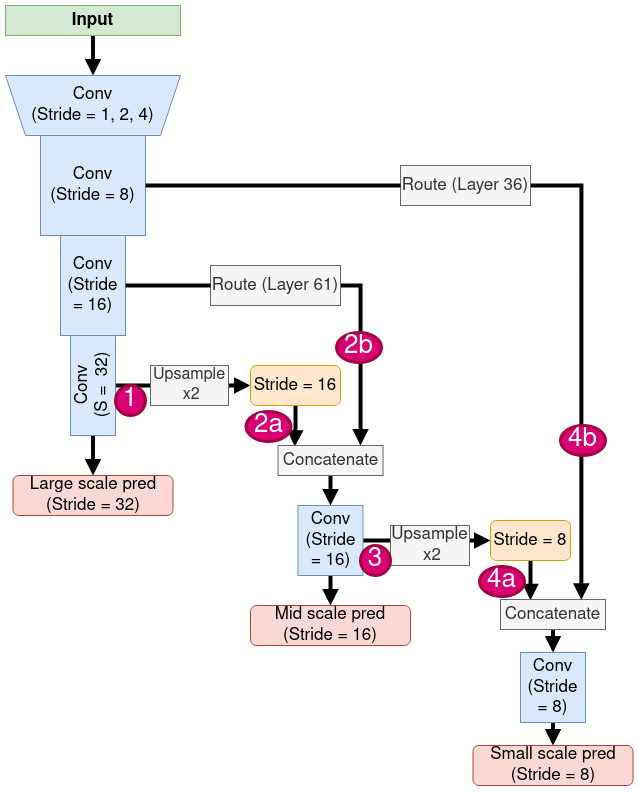
Figure 1: Structure of the YOLOv3 model. Blue boxes represent convolution layers, with their stride level labeled out. Prediction outputs are shown as red boxes, and there are 3 of them, with different stride levels. Pass-through connections are labeled as “Route”, and the layer from which these are taking out are put in parenthese (e.g. Layer 61. Indexing starts from 0). Route connections are labeled by red ellipses.
There are 6 types of blocks/sections in the config file:
2.2.1. [net]
This block contains some overall hyper-parameters of model, e.g. the learning rate, batch size, input image size etc.. We don’t have to take all of them from the config file at this stage, and we can provide the relevant information when they are needed (e.g. during training) later.
2.2.2. [convolutional]
Defines a convolutional block. The possible parameters in this block:
batch_normalize:1for including a batch normalization layer after the convolution layer,0otherwise.filters: number of filters in the convolution layer.size: size of the convolution kernel.stride: stride of the convolution kernel.pad: padding in the convolution layer.activation:leakyfor using the leaky ReLU activation,linearfor not using an activation function after convolution.
These convolution blocks all appear in sequences of different lengths in the model, and such sequences are represented by boxes with blue background in the model structure schematic in Figure 1. A complete table of the model structure is given in Table 1.
2.2.3. [shortcut]
A “shortcut” is a skip connection, or residual connection added across 2 convolution blocks, forming a residual block. The idea is from the residual network which significantly expanded the practically achievable depth of neural networks.
The
shortcut block has a single parameter: from, e.g. from=-3
means taking the output from 3 blocks backwards and using
that as the skip connection. The skip connection is added onto the
output from the block immediately before the shortcut block,
forming a residual block.
There is also an activation=linear parameter
in this block but we can safely ignore it.
2.2.4. [route]
A “route” is a pass-through connection that is introduced to enable multi-scale predictions.
In the schematic in Figure 1, the route connections are marked with red labels. There are 4 of them:
Labeled as
1in Figure 1. In the config file, this is defined as:[route] layers = -4
The
layers=-4parameter means we go back from thisrouteblock 4 blocks backwards, and take the output from there.Labeled as
2aand2bin Figure 1. In the config file, this is defined as:[route] layers = -1, 61
Note that this time the
layersparameter has 2 numbers:-1: means taking the output from the block before thisrouteblock. This corresponds to label2ain the figure.61: means taking the output from the block indexed61. Note that indexing starts from 0, so it is the 62nd block. This corresponds to label2bin the figure.
When the
layersparameter has 2 numbers, feature maps taken from these 2 routes are concatenated along the channel dimension, to form the output of thisrouteblock.Labeled as
3in Figure 1. In the config file, this is defined as:[route] layers = -4
So it is the same as route-1 except that we are taking feature maps from a different block.
Labeled as
4a,4bin Figure 1. In the config file, this is defined as:[route] layers = -1, 36
This is the similar as route-2.
2.2.5. [upsample]
upsample block has a single parameter stride, and they all take
the value of 2, meaning that we up-sample the feature map in the width
and height dimensions by a factor of 2, using interpolation (linear,
or nearest, doesn’t really matter).
You can find all 2 such blocks in Figure 1, labeled as Upsample
x2, and they appear after route-1 and route-3. That’s because
route-2a and route-2b are combining outputs at different stride
levels: route-1 takes a feature map at stride 32, and route-2b takes
one at stride 16, so the former one has to be scaled to stride 16
before they can be concatenated. Similarly for the route-4a, 4b case.
2.2.6. [yolo]
This is the detection outputting layer. In Figure 1, they are
represented by boxes with brick-red background color. There are 3 of
them, corresponding to detections at 3 size scales, so there are 3 yolo blocks in the config file:
large scale prediction
In the config file, this is defined as:
[yolo] mask = 6,7,8 anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326 classes=80 num=9 jitter=.3 ignore_thresh = .7 truth_thresh = 1 random=1
Only these parameters are relevant:
anchors: lists the (width, height) sizes of the 9 prescribed anchor boxes (you need to group them into (w, h) pairs yourself).mask: the 3 anchors used for this prediction layer is denoted by thismaskparameter. So6,7,8means taking the anchors from theanchorslist at indices6,7and8. Note that indexing starts from 0.classes: this is the number of classes to classify the detected object into.We will ignore the remaining parameters as they are either unimportant or could be implemented elsewhere. If you are interested, here has some more detailed explanations.
mid scale prediction
In the config file, this is defined as:
[yolo] mask = 3,4,5 anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326 classes=80 num=9 jitter=.3 ignore_thresh = .7 truth_thresh = 1 random=1
So only the
maskparameter is different.small scale prediction
Only the
maskparameter is changed to[yolo] mask = 0,1,2
The rest of the settings are the same as before.
2.3. Entire model structure
Table 1 below lists the entire model structure.
| Layer Index | Repeats | Layer Parameters | Current stride |
|---|---|---|---|
| 0 | 1 | Conv: 32x3x3 | 1 |
| 1 | 1 | Conv: 64x3x3 (s=2) | 2 |
| 2-4 | 1 | Conv: 32x1x1 Conv: 64x3x3 Residual -3 |
2 |
| 5 | 1 | Conv: 128x3x3 (s=2) | 4 |
| 6-11 | 2 | Conv: 64x1x1 Conv: 128x3x3 Residual -3 |
4 |
| 12 | 1 | Conv: 256x3x3 (s=2) | 8 |
| 13-36 | 8 | Conv: 128x1x1 Conv: 256x3x3 Residual -3 |
8 |
| 37 | 1 | Conv: 512x3x3 (s=2) | 16 |
| 38-61 | 8 | Conv: 256x1x1 Conv: 512x3x3 Residual -3 |
16 |
| 62 | 1 | Conv: 1024x3x3 (s=2) | 32 |
| 63-74 | 4 | Conv: 512x1x1 Conv: 1024x3x3 Residual -3 |
32 |
| 75-80 | 3 | Conv: 512x1x1 Conv: 1024x3x3 |
32 |
| 81 | 1 | Conv: (nanchors x (5 + nclasses))x1x1 | 32 |
| 82 | 1 | Yolo: large pred | 32 |
| 83 | 1 | Route: from 79 | 32 |
| 84 | 1 | Conv: 256x1x1 | 32 |
| 85 | 1 | Upsample: x2 | 16 |
| 86 | 1 | Route: cat 85 and 61 | 16 |
| 87-92 | 3 | Conv: 256x1x1 Conv: 512x3x3 |
16 |
| 93 | 1 | Conv: (nanchors x (5 + nclasses))x1x1 | 16 |
| 94 | 1 | Yolo: mid pred | 16 |
| 95 | 1 | Route: from 91 | 16 |
| 96 | 1 | Conv: 128x1x1 | 16 |
| 97 | 1 | Upsample: x2 | 8 |
| 98 | 1 | Route: cat 97 and 36 | 8 |
| 99-104 | 3 | Conv: 128x1x1 Conv: 256x3x3 |
8 |
| 105 | 1 | Conv: (nanchors x (5 + nclasses))x1x1 | 8 |
| 106 | 1 | Yolo: small pred | 8 |
2.4. Write the config-parsing code
Here is a simple function to read and parse the yolov3.cfg file and organize
the block definitions into a list of dict:
def parse_config(file_path): '''Parse the yolov3.cfg file Args: file_path (str): path to the yolov3.cfg file. Returns: net_config (dict): parameters in the [net] block. blocks (list): list of (block_type, block_dict) tuples. block_type: 'convolutional', 'route', 'shortcut', 'upsample' or 'yolo'. block_dict: a dict containing parameter key-value pairs of the block. ''' with open(file_path, 'r') as fin: lines = fin.readlines() blocks = [] block = {} for ii, lii in enumerate(lines): lii = lii.strip() if lii == '' or lii[0] == '#': continue if lii[0] == '[' and lii[-1] == ']': if len(block) == 0: # very 1st block new_block = lii[1:-1].strip().lower() else: # get beginning of a new block blocks.append((new_block, block)) new_block = lii[1:-1].strip().lower() block = {} else: # store block setting values key, value = lii.split('=') block[key.strip()] = value.strip() blocks.append((new_block, block)) net_config = blocks.pop(0)[1] return net_config, blocks
3. Create the Darknet-53 model
3.1. Some preparation work
Before jumping into model creation, let’s plan out a bit.
Firstly, below is the folder structure we are going to use to organize things:
YOLOv3_pytorch/
config/
yolov3.cfg # the downloaded yolov3.cfg file
load_config.py # contains our parse_config() function
data/
coco/ # coco detection data. You could link to somewhere else
ckpt/ # to store model weights
model.py # contains code to build the yolo model
train.py # contains code to train the yolo model
predict.py # contains code to make inferences using trained model
utils.py # to store general purpose utility functions
You can adopt any structure as long as it makes sense to you.
So how are we going to create the model?
Firstly, we are going to write the model-building code in the model.py
file.
We have created the parse_config() utility function that parses the
YOLOv3 model config file. This gives us a list of block definitions,
in the return value of module_list. We can read that list of blocks one by one, and
create a PyTorch module implementing the relevant functionality. Then
we store these individual block modules in some sort of container.
What type of container should we use? torch.nn.Sequential probably
won’t work, because remember the network is not a linear sequence, and
we have 3 branches (see Figure 1). So nn.ModuleDict is a
good alternative.
It is also noticed that we have several shortcut and route blocks,
which all require re-visiting of outputs from previous blocks. This
means that we need to cache some intermediate results. We are going to
use a dict to do this: use the block index as keys and block outputs
as values.
So we need to keep track of the block index as we go through the block
list, if it is a block whose output needs to be cached, we store this
block’s index into a list called cache_idx, so that when we pass an
input image through the model, we can check out from cache_idx whether
we need to cache a block’s output or not.
We already explained that when making route connections, making the stride
level compatible is a key factor. So, although not necessary, it would
be nice to also keep a record of the stride level as we build
along. Similarly, it might be worthwhile to also keep track of the
channel dimension as well. Because remember, unlike in Keras, you
need to provide the nn.Conv2d() initializer with the input channel
size. For a convolution layer after a route layer with concatenated
feature maps, the input channel size will be sum of 2 previous
ones. So storing such information could help.
Again, these are not necessary. You don’t even need to have a
parse_config() function to implement a Darknet, as long as the built
model works.
So that’s the plan. Now show the code.
3.2. Start the Darknet53 module
We start the Darknet53 module definition like this:
class Darknet53(nn.Module): def __init__(self, config): nn.Module.__init__(self) self.config = config self.width = config['width'] self.height = config['height'] self.n_classes = config['n_classes'] self.module_list = config['module_list'] self.layers, self.stride_dict, self.channel_dict,\ self.cache_idx, self.yolo_layers =\ build_modules(self.module_list, self.n_classes) def forward(self, x): pass
The config input argument is a dict containing necessary
information of the model configurations, and can be obtained using the
following:
CONFIG_FILE = './config/yolov3.cfg' net_config, module_list = parse_config(CONFIG_FILE) config = {'net': net_config} config['module_list'] = module_list config['width'] = 416 config['height'] = 416 config['n_classes'] = 80
Then in the __init__() initializer, we call a build_modules()
function to create the modules. It returns:
self.layers: adict, with block indices as keys andnn.Moduleimplementations as values.self.stride_dict: adict, with block indices as keys and the current stride level as values.self.channel_dict: adict, with block indices as keys and the module’s output channel dimension size as values.self.cache_idx: aliststoring indices of blocks whose outputs need to be cached.self.yolo_layers: aliststoring yolo blocks.
Next, we implemented the 5 types of blocks.
3.3. The convolutional module
Below is a ConvBNReLU module that implements a convolution layer
with optional batch normalization and LeakyReLU activation:
class ConvBNReLU(nn.Module): def __init__(self, c_in, c_out, kernel_size, stride, padding, bn, act): nn.Module.__init__(self) self.bn = bn bias = 1 - bn self.layers = nn.Sequential() self.layers.add_module('conv', nn.Conv2d(c_in, c_out, kernel_size, stride, padding, bias=bias)) if bn: self.layers.add_module('bn', nn.BatchNorm2d(c_out)) if act == 'leaky': self.layers.add_module('leaky', nn.LeakyReLU(0.1)) def forward(self, x): return self.layers(x)
Note that if batch normalization is used (bn=1),
then the convolution layer has no bias term. It is not
crucial if you add the bias, but thus built Darknet53 won’t be able to
work with the pre-trained weights.
3.4. The shortcut module
There is really no special form of computations in this layer, so we
only need to create a dummy nn.Module for shortcut. It only needs
to store the index of the block from which the skip connection is
taken.
class Shortcut(nn.Module): def __init__(self, from_idx): nn.Module.__init__(self) self.from_idx = from_idx
3.5. The route module
Similar as shortcut, a dummy nn.Module is sufficient. The
logic of this block will be implemented in the forward() method of
Darknet53.
class Route(nn.Module): def __init__(self, idx1, idx2): nn.Module.__init__(self) self.idx1 = idx1 self.idx2 = idx2
3.6. The upsample module
upsample is also a simple block:
class Upsample(nn.Module): def __init__(self, scale): nn.Module.__init__(self) self.scale = scale def forward(self, x): x = F.interpolate(x, scale_factor=self.scale, mode='nearest') return x
There is no trainable parameters involved in the interpolation
operation, so technically you can make the upsample block into a
dummy nn.Module as well, and call torch.nn.functional.interpolate()
inside the forward() method of Darknet53 to achieve the same effect.
3.7. The yolo module
This is the prediction outputting layer. There is a bit more going on here. Code first:
class Yolo(nn.Module): def __init__(self, n_classes, anchors, stride): nn.Module.__init__(self) self.n_classes = n_classes self.anchors = torch.tensor(anchors).float() self.stride = stride self.n_anchors = len(anchors) self.grid_mesh = {} def forward(self, x): b, _, h, w = x.shape x = x.view([b, self.n_anchors, -1, h, w]).permute(0, 1, 3, 4, 2).contiguous() # x: [b, anchors, h, w, features] if not self.training: if (h, w) not in self.grid_mesh: grid_yy, grid_xx = torch.meshgrid(torch.arange(h), torch.arange(w), indexing='ij') grid_yy = grid_yy.view([1, 1, h, w]) grid_xx = grid_xx.view([1, 1, h, w]) self.grid_mesh[(h, w)] = (grid_xx, grid_yy) grid_xx, grid_yy = self.grid_mesh[(h, w)] grid_xx = grid_xx.to(x.device) grid_yy = grid_yy.to(x.device) # transform x, y x[..., :2] = torch.sigmoid(x[..., :2]) x[..., 0] += grid_xx x[..., 1] += grid_yy x[..., :2] *= self.stride # transform w, h x[..., 2:4] = torch.exp(x[..., 2:4]) * self.anchors.view(1, -1, 1, 1, 2).to(x.device) # sigmoid objectness scores and cls predictions x[..., 4:] = torch.sigmoid(x[..., 4:]) x = x.view([b, -1, self.n_classes + 5]) return x
Firstly, we store some attributes:
n_classes: number of classes in the classification task.anchors: list of (w,h) tuples of this yolo layer’s anchor boxes. Recall that in YOLOv3 there are 3 anchor boxes for each scale’s predictions. Soanchorsshould contain 3 tuples.stride: as explained in part-1, the stride level of a feature map is an important variable for the localization task. So we definitely need to store it.
In the forward() method, we first manipulate the shape of the input
tensor:
b, _, h, w = x.shape x = x.view([b, self.n_anchors, -1, h, w]).permute(0, 1, 3, 4, 2).contiguous()
Recall that in PyTorch, 2D convolution layers output tensors in shape of
[b, c, h, w]
h and w are the feature maps sizes (at this stride level), and c
is the channel size, which should be:
n_anchors * (5 + n_classes)
So after the above reshaping and permutation, tensor x has a
shape of
[b, n_anchors, h, w, 5 + n_classes]
For training, that’s all we need to do, and we just return x. I’ll
give the cost computation code in a later post.
For inference, we need to formulate the predictions.
Firstly, recall that each prediction consists of these elements:
[x, y, w, h, obj, c1, c2, ..., ck]
Now take the sigmoid of the raw location predictions:
x[..., :2] = torch.sigmoid(x[..., :2])
This is the \(\sigma(t_x)\) and \(\sigma(t_y)\) part of the location prediction equation:
\begin{equation} \begin{aligned} b_x = & \sigma(t_x) + c_x \\ b_y = & \sigma(t_y) + c_y \\ b_w = & p_w e^{t_w} \\ b_h = & p_h e^{t_h} \\ \end{aligned} \end{equation}Then get the \(c_x\) and \(c_y\) terms:
if (h, w) not in self.grid_mesh: grid_yy, grid_xx = torch.meshgrid(torch.arange(h), torch.arange(w), indexing='ij') grid_yy = grid_yy.view([1, 1, h, w]) grid_xx = grid_xx.view([1, 1, h, w]) self.grid_mesh[(h, w)] = (grid_xx, grid_yy) grid_xx, grid_yy = self.grid_mesh[(h, w)] grid_xx = grid_xx.to(x.device) grid_yy = grid_yy.to(x.device)
Add them to get bounding box locations, in feature map coordinate:
x[..., 0] += grid_xx x[..., 1] += grid_yy
This is doing \(b_x = \sigma(t_x) + c_x\) and \(b_y = \sigma(t_y) + c_y\).
To transform from feature map coordinate to image coordinate, multiply with the stride (more on this in the The localization taks section of part-1):
x[..., :2] *= self.stride
Then get the width and height of bounding box prediction:
# transform w, h x[..., 2:4] = torch.exp(x[..., 2:4]) *\ self.anchors.view(1, -1, 1, 1, 2).to(x.device)
This is doing the \(b_w = p_w e^{t_w}\) and \(b_h = p_h e^{t_h}\) part.
Then, the objectness score and n-way classifications are all probability values, so we sigmoid them all:
x[..., 4:] = torch.sigmoid(x[..., 4:])
Finally, re-arrange the predictions to a shape of
[b, num_of_predictions, 5 + n_classes]
This is done using:
x = x.view([b, -1, self.n_classes + 5])
3.8. The module-building function
Having all the building blocks ready, let’s write the function that assembles them. Finished code given below:
def build_modules(module_list, n_classes): '''Build modules for the Darknet53 model Args: module_list (list): list of dicts, each containing parameters of a block. n_classes (int): number of classes in the classification task. Returns: layer_dict (dict): keys are block indices, values are modules. stride_dict (dict): keys are block indices, values are current stride level of this block's output. channel_dict (dict): keys are block indices, values are the channel dimension size of this block's output. cache_idx (list): indices of blocks whose output need to be cached during forward pass. yolo_layers (list): list of yolo modules. ''' stride_dict = {-1: 1} # keep track of layer strides channel_dict = {-1: 3} # keep track of layer channels layer_dict = nn.ModuleDict() # store layers cache_idx = [] # store indices of layers whose results needs cache yolo_layers = [] # store yolo output layers for ii, (mod_type, mod_dict) in enumerate(module_list): mod_id = len(layer_dict) cur_channel = channel_dict[mod_id-1] cur_stride = stride_dict[mod_id-1] if mod_type == 'net': continue elif mod_type == 'convolutional': kernel_size = int(mod_dict['size']) stride = int(mod_dict['stride']) pad = int(mod_dict['pad']) bn = int(mod_dict.get('batch_normalize', 0)) act = mod_dict['activation'] if module_list[ii+1][0] != 'yolo': c_out = int(mod_dict['filters']) else: mask = module_list[ii+1][1]['mask'] len_anchors = len(mask.split(',')) c_out = (5 + n_classes) * len_anchors padding = (kernel_size - 1) // 2 if pad else 0 layer = ConvBNReLU(cur_channel, c_out, kernel_size, stride, padding, bn, act) cur_stride *= stride cur_channel = c_out layer.stride = cur_stride elif mod_type == 'shortcut': from_idx = int(mod_dict['from']) if from_idx < 0: from_idx = mod_id + from_idx layer = Shortcut(from_idx) cache_idx.append(from_idx) elif mod_type == 'route': idx = mod_dict['layers'] if ',' in idx: idx1, idx2 = map(int, idx.split(',')) else: idx1, idx2 = int(idx), None if idx1 < 0: idx1 = mod_id + idx1 cache_idx.append(idx1) if idx2 is None: cur_channel = channel_dict[idx1] else: if idx2 < 0: idx2 = mod_id + idx2 cur_channel = channel_dict[idx1] + channel_dict[idx2] cache_idx.append(idx2) cur_stride = stride_dict[idx1] layer = Route(idx1, idx2) elif mod_type == 'upsample': stride = int(mod_dict['stride']) cur_stride = int(cur_stride / stride) layer = Upsample(stride) elif mod_type == 'yolo': mask = list(map(int, mod_dict['mask'].split(','))) anchors = mod_dict['anchors'].split(',') anchors = list(map(int, map(str.strip, anchors))) anchors = list(zip(anchors[::2], anchors[1::2])) anchors = [anchors[ii] for ii in mask] cur_channel = (5 + n_classes) * len(anchors) layer = Yolo(n_classes, anchors, cur_stride) yolo_layers.append(layer) # store layer, current stride, current channel layer_dict[str(mod_id)] = layer stride_dict[mod_id] = cur_stride channel_dict[mod_id] = cur_channel ''' keys = list(layer_dict.keys()) keys = list(map(int, keys)) keys.sort() for kk in keys: print('layer',kk,'stride=',stride_dict[int(kk)],'channel=',channel_dict[int(kk)]) print(cache_idx) ''' return layer_dict, stride_dict, channel_dict, cache_idx, yolo_layers
A more detailed break down of the function and some points:
3.8.1. Overall structure
The input module_list is a list of (mod_type, mod_dict) tuples. When
iterating through module_list, we first get the block’s index, and
the stride and channel size of its immediate predecessor:
stride_dict = {-1: 1} # keep track of layer strides channel_dict = {-1: 3} # keep track of layer channels layer_dict = nn.ModuleDict() # store layers cache_idx = [] # store indices of layers whose results needs cache yolo_layers = [] # store yolo output layers for ii, (mod_type, mod_dict) in enumerate(module_list): mod_id = len(layer_dict) cur_channel = channel_dict[mod_id-1] cur_stride = stride_dict[mod_id-1]
Depending on what mod_type is, 'convolutional', 'upsample' etc.,
we build different modules:
if mod_type == 'net': continue elif mod_type == 'convolutional': # ... elif mod_type == 'shortcut': # ... elif mod_type == 'route': # ... elif mod_type == 'upsample': # ... elif mod_type == 'yolo': # ...
Then at the end of the iteration, we store the built module into the
layer_dict dict, and update the current stride level and channel
size:
# store layer, current stride, current channel layer_dict[str(mod_id)] = layer stride_dict[mod_id] = cur_stride channel_dict[mod_id] = cur_channel
The stride level is changed only in 2 ways:
- down-sampling (stride x2) by a
convolutionalblock which uses astride=2convolution. - up-sample (stride /2) by an
upsampleblock.
3.8.2. The convolutional block before a yolo block
For a convolutional block, we read the size, stride
etc. parameters. But we also do something special if the next
block is a yolo block:
if module_list[ii+1][0] != 'yolo': c_out = int(mod_dict['filters']) else: mask = module_list[ii+1][1]['mask'] len_anchors = len(mask.split(',')) c_out = (5 + n_classes) * len_anchors
This is because if that is the
case, then the output channel of this conv layer needs to be n_anchors * (5 +
n_classes). n_classes is in the config dict we stored
earlier, and n_anchors is given by the mask parameter in the yolo
block that follows.
In the yolov3.cfg, the output channel is hard coded to be 255,
that works for n_classes = 80 and n_anchors = 3. So this
arrangement makes it earlier to adapt to other class numbers, or
anchor box numbers if you decide to change that as well.
3.8.3. Store the indices of shortcut and route blocks
As mentioned earlier, we need to store the from_idx of a shortcut
block to cache_idx, because
that’s an intermediate output needs to be cached.
Similarly, we also store idx1 and/or indx2 indices taken from a route
block into the cache_idx list.
3.8.4. The str and int types of block indices
nn.ModuleDict requires str type as keys. So when storing modules
into layer_dict, the block index is converted to str:
layer_dict[str(mod_id)] = layer
For stride_dict and channel_dict, we use int type indices as keys.
3.8.5. Summarize the build_module() function
- Call the
parse_config()function to get block definitions stored in alist. - Go through the block definition list, and for each new block:
- Create a new module, give it a 0-based index.
- Store the module in a
ModuleDict, using index (cast tostr) as key. - Store the module’s stride level in a
stride_dictdict, using index as key. - Store the module’s channel dimension size in a
channel_dictdict, using index as key. - Store the module in a
yolo_layerslist, if it is a[yolo]block.
- Return collected things.
3.9. The forward() method of Darknet53
This is the last missing piece. Code first:
def forward(self, x): cache_dict = {} # cache intermediate outputs outputs = [] # collect outputs from yolo layers for idx, layer in self.layers.items(): idx = int(idx) if isinstance(layer, (ConvBNReLU, Upsample)): x = layer(x) elif isinstance(layer, Shortcut): skip = cache_dict[layer.from_idx] x += skip elif isinstance(layer, Route): x = cache_dict[layer.idx1] if layer.idx2 is not None: x = torch.cat([x, cache_dict[layer.idx2]], dim=1) elif isinstance(layer, Yolo): x = layer(x) outputs.append(x) # cache intermediate results if idx in self.cache_idx: cache_dict[idx] = x if not self.training: outputs = torch.cat(outputs, dim=1) return outputs
The code is fairly simple. We just pass the input tensor x through
all the blocks, and depending on what type of block, do different
things:
- For
convolutionalorupsampleblocks: call itsforward()method. - For
shortcutblock: read from cache the residual term and add it tox. - For
routeblock: if it has only 1 index (route1or3in Figure 1), read from cache and use the cache as the new current statex. If it has 2 indices (route2a2bor4a4bin Figure 1), read from cache 2 previous outputs, concatenate them and use as the new current statex. - For
yoloblock: call itsforward()method and collect the output. - If the block’s output needs to be cached, store it in
cache_dict.
4. Test drive
I was taught that when writing a neural network, it is a good practice
to pass it some random numbers and see the if the program terminates
normally and if you get the expected shape. Let’s do this to test out
our Darknet53:
if __name__ == '__main__': CONFIG_FILE = './config/yolov3.cfg' from config import load_config net_config, module_list = load_config.parse_config(CONFIG_FILE) config = {'net': net_config} config['module_list'] = module_list config['width'] = 416 config['height'] = 416 config['n_classes'] = 80 model = Darknet53(config) x = torch.randn([4, 3, 416, 416]) y = model(x) for yii in y: print(yii.shape)
If you get outputs like the following, then it is a good run:
torch.Size([4, 3, 13, 13, 85]) torch.Size([4, 3, 26, 26, 85]) torch.Size([4, 3, 52, 52, 85])
5. Summary
This post talks about building the Darknet-53 network using
PyTorch. The same model can be implemented simply by following the
paper and/or the official config file and just writing up the nn.Module
class. Alternatively, we can programmatically parse the official
config file and build the nn.Module accordingly. We followed the 2nd path in
this post.
There are 5 types of blocks in the Darknet-53 model:
convolutional: 2D convolution layer with batch normalization and LeakyReLU activation.shortcut: skip connection in a residual block.route: pass-through connections with bigger jumps thanshortcut, used to create multi-scale predictions.upsample: up-sample the width and height dimensions.yolo: prepare prediction outputs.
For each type, we created an nn.Module to represent/implement its
functionality.
We created a parse_config() function to read and parse the official
yolov3.cfg config file.
We create a build_modules() function to read the output from
parse_config(), and assemble the Darknet53 model.
In the next post, we will load the pre-train weights into our
Darknet53 and perform some inferences.
Created: 2022-06-22 Wed 22:37


